



强化学习(RL)在废话语模子和 2D 图像生成中大获见效后,初次被系统性拓展到文本到 3D 生成界限!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理致密化的双重挑战,征询者们初次系统征询了 RL 在 3D 自回想生成中的利用!
来自上海东说念主工智能实验室、西北工业大学、香港汉文大学、北京大学、香港科技大学等机构的征询者提倡了 AR3D-R1,这是首个强化学习增强的文本到 3D 自回想模子。该使命系统征询了奖励假想、RL 算法和评估基准,并提倡 Hi-GRPO——一种端倪化强化学习范式,通过分离全局结构推理与局部纹理精修来优化 3D 生成。同期引入全新基准 MME-3DR,用于评估 3D 生成模子的隐式推贤慧力。
实验标明 AR3D-R1 在 Kernel Distance 和 CLIP Score 上均获取权贵普及,达到 0.156 和 29.3 的优异收货。

论文标题:Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
代码勾通:https://github.com/Ivan-Tang-3D/3DGen-R1
强化学习利用于 3D 生成的挑战
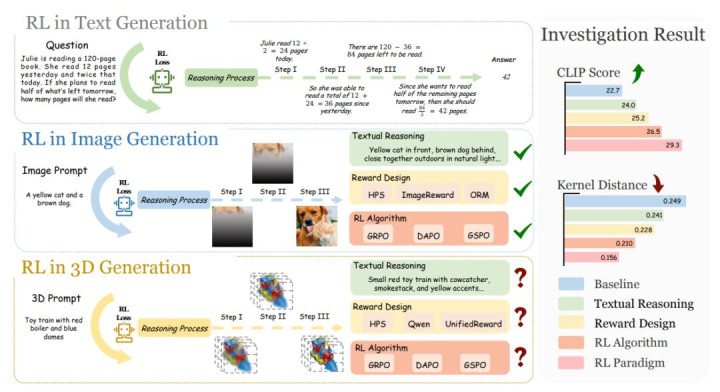
强化学习在废话语模子(如 DeepSeek-R1)和 2D 图像生成中已被阐明大致灵验普及模子性能,但将 RL 利用于 3D 生成仍濒临独到挑战:
空间复杂性更高:3D 物体需要同期保握全局几何一致性和局部纹理致密度,比 2D 图像的空间复杂性跳动一个维度。
奖励假想艰难:何如假想既能评估全局结构又能捕捉局部细节的奖励函数是要津难题。
现存基准局限:现时的文本到 3D 基准主要关怀物体各类性,无法灵验评估模子的隐式推贤慧力。
算法明锐性:3D 生成对奖励假想和 RL 算法的选拔高度明锐,需要系统性的征询来教学执行。
在此前的使命中,3D 模子大多停留在「预考验 + 微调」框架,真的将 RL 引入 3D 生成的一步,还无东说念主系统迈出。
从「推理」到「造物」:
AR3D-R1 的举座框架
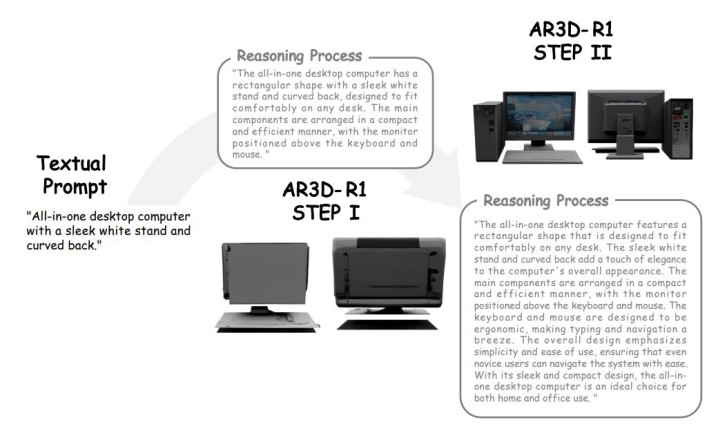
AR3D-R1 构建在龙套 3D 生成模子 ShapeLLM-Omni 之上,引入了一个推理驱动的 3D 生成经由:
先想一想:模子会先凭据文本辅导生成一段高层语义推理(近似 CoT),贪图出物体的苟简结构、关系与作风。
再发轫造:随后,推理成果会当作「中间贪图」,奏凯教学龙套 token 的 3D 生成过程。
这让 AR3D-R1 不再是「凭本能画 3D」,而是先构想、再搭骨架、终末上细节——真的把 RL 驱动的「会想」智力,迁徙到了「会造」的 3D 天下里。
奖励假想与 RL 算法的系统性征询
在奖励假想方面,征询者评估了多个奖励维度和模子选拔,得出以下要津发现:

东说念主类偏好对都至关遑急:与东说念主类审好意思偏好对都的奖励信号大致权贵普及生成质地。
通用多模态模子具有鲁棒性:令东说念主骇怪的是,通用多模态模子在评估 3D 联系属性时施展出强盛的鲁棒性,未必以致优于有利的 3D 评估模子。
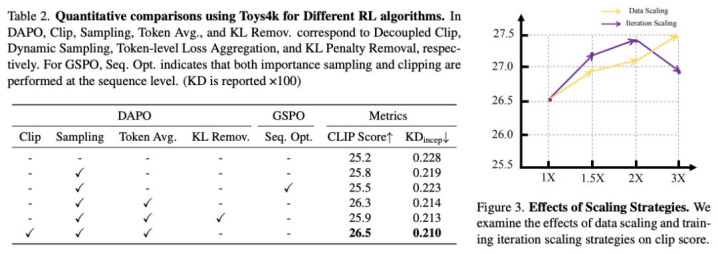
在 RL 算法征询方面,征询者真切分析了 GRPO 的多个变体,包括模范 GRPO、引入 token 级平均与动态采样的 DAPO,和更偏序列级操作的 GSPO 等:
Token 级优化更灵验:比较反映级优化,token 级别的亏损平均能更好地捕捉生成过程中的全局结构相反。
动态采样计谋足以清醒考验:关于文本到 3D 生成任务,无需复杂的考验清醒手艺。
数据范畴和迭代次数的膨大均能灵验普及性能:但一味堆叠 RL 迭代反而可能引入过拟合或样式垮塌,需要致密校准。
这些发现为 3D 生成中的 RL 利用提供了系统性教学。
Hi-GRPO:
端倪化强化学习范式
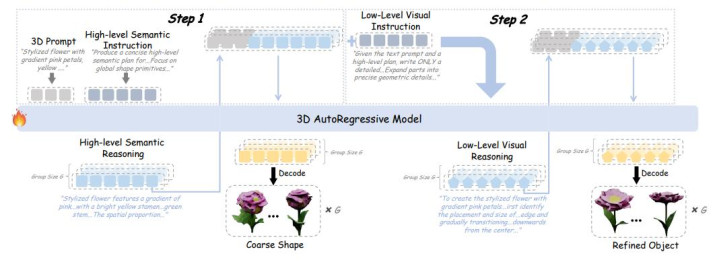
受 3D 生成当然端倪结构的启发——模子领先构建全局几何,然后精修局部纹理(这与东说念主类 3D 感知过程一致),征询者提倡了 Hi-GRPO(Hierarchical GRPO)端倪化强化学习范式。
Hi-GRPO 的中枢想想是在单次迭代中聚会优化端倪化 3D 生成:
全局贪图阶段:模子领先针对文本辅导进行全局结构贪图,生成高层语义推理来教学粗略体式生成。
局部精修阶段:模子接受运行推理成果和原始文本辅导,生成纹理致密化的 3D 物体。
专用奖励集成:为粗略阶段和精修阶段分裂假想有利的奖励模子集成,斟酌组相对奖励来优化两个阶段。
通过这种端倪化假想,Hi-GRPO 大致在保证全局几何一致性的同期,致密优化局部纹理细节,结束从粗到精的渐进式 3D 生成。
MME-3DR:
评估 3D 生成推贤慧力的新基准
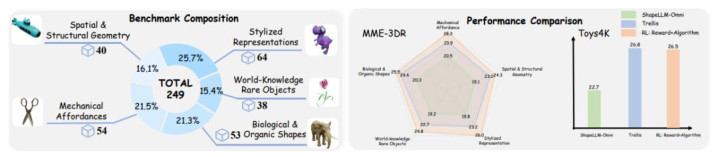
现存的文本到 3D 基准,更多磨真金不怕火的是物体各类性,而不是推贤慧力。模子在简便 prompt 上施展可以,但一遭遇复杂条目就时常「翻车」。为此,论文提倡了全新的推理型 3D 基准 MME-3DR,障翳五大高难类别:
空间与结构几何(复杂构型、相对位置关系)
机械可供性(能不成「看起来就能动起来」)
生物与有机体式
依赖天下学问的萧疏物体
作风化抒发(作风、材质、抽象度的抽象纵容)
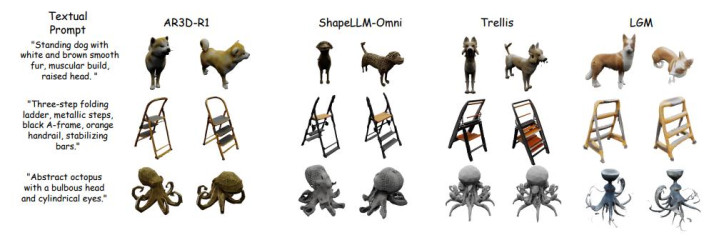
在这一更残酷的场景下:传统 text-to-3D 模子大都出现垮塌,要么结构高大,要么作风跑偏。而 RL 考验之后的 AR3D-R1 在五大类别上都有赫然普及,同期在多个 benchmark 上特出 Trellis 等模子,展现出更强的隐式 3D 推贤慧力。
定性定量分析

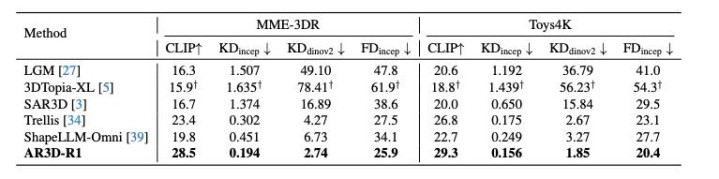
定量实验成果标明,AR3D-R1 在多个想法上获取了权贵普及:
Kernel Distance 达到 0.156,标明生成的 3D 物体散播与真的数据散播高度接近。
CLIP Score 达到 29.3,标明生成成果与文本辅导的语义对都质地权贵普及。
在 Toys4K 等现存数据集和新引入的 MME-3DR 基准上均展现出优厚性能,在几何一致性和纹理质地点面均有赫然更始。
定性实验中,征询者展示了 AR3D-R1 在推理过程中了了的从粗到精进展。模子领先构建合理的全局几何结构,然后渐渐添加细节纹理,生成高质地的 3D 物体。可视化成果考据了 Hi-GRPO 端倪化范式和专用奖励集成计谋在普及 3D 生成质地点面的灵验性。
AR3D-R1 的见效秀气着强化学习在文本到 3D 生成界限的初次系统性冲破,为构建更智能、更具推贤慧力的 3D 生成模子设备了新标的。改日,这么的智力可以当然延长到:
具身智能与机器东说念主:从当然话语到 3D 场景再到交互有盘算推算。
游戏与推行创作:快速生成结构合理、细节丰富的 3D 资源。
AR/VR 与数字孪生:在复杂拘谨和多模态反馈下进行 3D 推理与生成。